 連載 連載.NET&Windows Vistaへ広がるDirectXの世界 第7回 プログラマブル・シェーダによる積極的なGPUの活用 NyaRuRuMicrosoft MVP Windows - DirectX(Jan 2004 - Dec 2007) 2007/05/08 |
|
|
■描画の流れ
ソース・コードと一緒に読み進める方は、サンプル1を開いていただきたい。
Direct3Dによるポリゴン描画は、データを加工するパイプライン状の仕組みと見ることができることから、しばしばレンダリング・パイプラインと呼ばれる(「第1回 2. 高速描画の裏事情」を参照)。
 |
| Direct3Dのパイプライン構造 |
| 頂点ストリームから読み取られた頂点情報は、頂点シェーダに送られる。頂点シェーダの出力はラスタライザを経てスクリーン上のピクセルに分解され、それぞれのピクセルごとにピクセル・シェーダに送られる。 |
CPU同様、パイプラインの各段を並行的に動作させることによる高クロック化も進んでおり、GPUの高スループットを支える大きな要因となっている。そして、GPUはCPUよりも急速に並列化(パイプラインの多重化)が進んでいる点も見逃せない。近年のGPUでは、頂点パイプ、ピクセル・パイプともに複数備えるのが一般的で、複数頂点または複数ピクセルを同時に処理することでスループットを稼いでいる。
従来、頂点シェーダやピクセル・シェーダはそれぞれ用途が固定されたモジュールとして実装されていたため、ハードウェアの段階でそれぞれの並列度が決まっていた。一般的に頂点数よりも塗りつぶしピクセル数の方が多くなることから、頂点パイプよりもピクセル・パイプに高い並列度を持たせたハードウェアがほとんどである。
しかし、今後はプログラマブル・シェーダをグラフィックス以外に応用する場面も増えてくると予想され、あらかじめ並列度を固定してしまうより、両用型の汎用計算ユニットを多数搭載し、動的に配分比を決定した方がコスト・パフォーマンス上有利という考え方が強くなってきている。このようなGPUはユニファイド・シェーダ型と呼ばれ、Xbox360に搭載されているGPUや、Direct3D 10世代のGPUですでに実用化されている。
実際、今回サンプルで示すマンデルブロ集合の計算のように、ピクセル・シェーダへの負荷が非常に高く、頂点シェーダはほとんど何もしない場合は、ユニファイド・シェーダ型の方が良いコスト・パフォーマンスを示すだろう。その意味でも、ぜひXbox360でサンプルを実行して、その性能を確かめてみていただきたい。
■頂点ストリームの設定
 |
GPUからはファイルI/OといったOSの機能を直接利用することはできないため、描画に使用するポリゴン・データはいったんメイン・メモリに読み込む必要がある。ポリゴン・データの実体は頂点データの配列である。
メイン・メモリ上のデータをGPUに渡すには、頂点バッファと呼ばれる専用のバッファに一度データを格納してから描画パイプラインに投入する方法と、メイン・メモリ上のメモリ・アドレスを描画APIに直接指定する方法の2通りの方法がある。XNAでは、前者がVertexBufferクラスを使用した描画方法に対応し、後者がDrawUserPrimitive<T>クラスおよびDrawIndexedUserPrimitive<T>クラスに対応する。
汎用コンピュータであるPC環境では、頂点バッファを使用する方法が一般的だ。これはPC環境ではメイン・メモリとGPUローカル・メモリの間の通信が高コストなためで、頂点データの読み込みと同時に頂点バッファに転送し、あらかじめGPUの近くに移しておくことにより、メモリ転送がボトルネックになるのを防ぐわけである。
このように書いてしまうと、PC環境では頂点バッファを必ず使用すべきなのかという質問を受けることが多いのだが、今回の記事のようにピクセル・パイプに激しく負荷をかける場合は、仮に頂点バッファを使用しなかったとしても劇的にパフォーマンスが悪化する可能性は低いだろう。
一方、ゲーム機として設計されたXbox360では、メイン・メモリから直接頂点データを転送するコストはPCよりもずっと小さいといわれている。とはいえ、今回は練習もかねて頂点バッファを使用した描画を行うこととしよう。
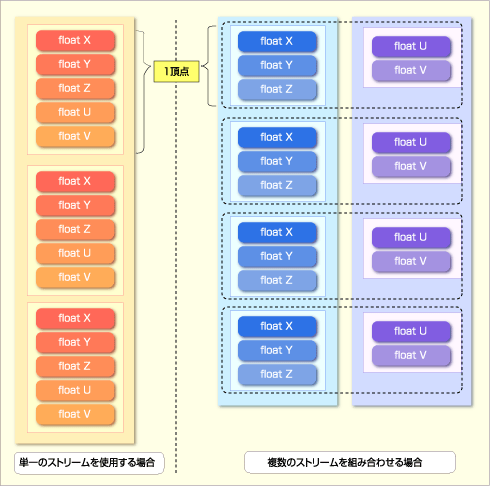 |
| 頂点バッファのメモリ・レイアウトの自由度 |
| 頂点バッファはそのまま描画APIに渡されるのではなく、いったんデバイスの頂点ストリームにセットしてから描画APIを呼び出すという形を取る。このとき、頂点バッファのメモリ・レイアウトには2つの自由度が存在する。 1つは、頂点バッファ上の配列要素にC#の構造体のようなユーザー定義型を使用できることだ。そのため、頂点バッファへの書き込みは.NETの構造体配列を単純にメモリ転送するという形で実装できる。 もう1つの自由度は、複数の頂点データ配列から配列要素を1つずつ取り出し、1つの頂点データとして結合できることである。この機能のおかげで、例えば形状が同じでUV情報(=画面左上から相対的にどの位置にあるかの計算に利用される座標)のみ異なる2つの形状データを、UV情報のみを格納した2つの配列と、そのほかの共通部分のみを格納した1つの配列にデータを分割することができる。従って共通部分の頂点バッファは1つで済むため、メモリを節約できるというわけだ。 なお、頂点バッファを経由せず、描画APIに直接メイン・メモリのポインタを渡す方法の場合は、単一の頂点ストリーム使用時と同じ扱いになる。 |
本記事のサンプルでは、頂点はたったの2つの情報のみを持つ。1つは位置情報で、スクリーンの4隅を指定し、スクリーン全体のピクセルを塗りつぶすために必要となる。もう1つはUV座標で、各ピクセルが画面左上から相対的にどの位置にあるかの計算に利用している。これらの情報を含んだ最もシンプルなC#の頂点構造体は、次のようになるだろう。
|
|
| 最もシンプルなC#の頂点構造体 |
C#コンパイラはデフォルトで構造体にStructLayout属性(System.Runtime.InteropServices名前空間)で「LayoutKind.Sequential」を指定するので、フィールドは定義順にメモリ上に置かれることが保証される。従って、MyVertex配列のマネージ・ヒープ中でのメモリ・レイアウトは次のようになる。
 |
| マネージ・ヒープ中のMyVertex配列のメモリ・レイアウト |
| MyVertex構造体は2つのVector2構造体からなり、Vector2構造体は2つのfloat型からなることから、MyVertex構造体はちょうどfloat型が4つ並んだメモリ・レイアウトをしている。 その結果、マネージ・ヒープ上のMyVertex構造体配列は、「配列の要素数×4」個のfloat型の配列と同じメモリ・レイアウトとなる。 Large Object Heap(第6回参照)に含まれる場合を除いて、マネージ・ヒープ上のオブジェクトはアドレスが移動することがあるため、構造体配列のメモリ・イメージを直接扱うにはアンセーフ・モードでオブジェクトのアドレスを固定(Pinning)する必要がある。 |
それでは実際に頂点バッファを作成し、4つの頂点をセットしてみよう。サンプル1では、LoadGraphicsContentメソッドでこの処理を行っている。
|
|
| 頂点バッファを作成し、4つの頂点をセットするサンプル・コード |
SetData<T>メソッドのパラメータに指定できるのは値型の配列のみである。これはSetData<T>メソッドが内部で、値型配列のアドレスを固定し、アンセーフ・コードによるメモリ・コピーを行っているためだ。
 |
| VertexBuffer.SetData<T>メソッドによる頂点バッファへのデータ転送 |
| SetData<T>メソッドによる頂点バッファへのデータの転送は、アンセーフ・コードでの単純なメモリ・コピーとして実装されているため、P/Invokeのようにマーシャリングは発生しない。例えばCLRの標準マーシャラはデフォルトでbool型をWin32 BOOL型にマーシャリングするが、SetData<T>メソッドではそういった変換は一切行われない。 |
作成した頂点バッファをデバイスの頂点ストリームに結び付けることで、実際に頂点バッファからデータが読み取られるようになる。これにはGraphicsDevice.SetSourceメソッドを使用するのだが、このメソッドもメモリ・レイアウトについて注意が必要である。サンプル・コードでは以下のように処理している。
|
|
| SetSourceメソッドの使い方 | |
| 第2パラメータ(offsetInByte)には頂点バッファ上のゼロ点を選ぶバイト・オフセットを、第3パラメータ(vertexStride)には配列要素1つ分が何バイトかを指定する。 VertexBuffer.SetData<T>メソッドによってコピーした頂点バッファの内容は、マネージ・ヒープ中での値型配列のメモリ・レイアウトと同じになるため、例えば第3パラメータに渡す値は、Marshal.SizeOfメソッドの返す値ではなくsizeof演算子の返す値を用いるべきである。 なお、頂点ストリームは先ほども述べたように複数使用できるのだが、今回使用するのは最初の1本目のみである。 |
頂点ストリームの設定ができたところで、次に行うのはストリーム上のデータを頂点シェーダの入力にマッピングする作業だ。
| INDEX | ||
| .NET&Windows Vistaへ広がるDirectXの世界 | ||
| 第7回 プログラマブル・シェーダによる積極的なGPUの活用 | ||
| 1.トピックの由来とサンプル・コード | ||
| 2.描画の流れ(1) | ||
| 3.描画の流れ(2) | ||
| 4.描画の流れ(3) | ||
| 5.描画の実行 | ||
| 「.NET&Windows Vistaへ広がるDirectXの世界」 |
- 第2回 簡潔なコーディングのために (2017/7/26)
ラムダ式で記述できるメンバの増加、throw式、out変数、タプルなど、C# 7には以前よりもコードを簡潔に記述できるような機能が導入されている - 第1回 Visual Studio Codeデバッグの基礎知識 (2017/7/21)
Node.jsプログラムをデバッグしながら、Visual Studio Codeに統合されているデバッグ機能の基本の「キ」をマスターしよう - 第1回 明瞭なコーディングのために (2017/7/19)
C# 7で追加された新機能の中から、「数値リテラル構文の改善」と「ローカル関数」を紹介する。これらは分かりやすいコードを記述するのに使える - Presentation Translator (2017/7/18)
Presentation TranslatorはPowerPoint用のアドイン。プレゼンテーション時の字幕の付加や、多言語での質疑応答、スライドの翻訳を行える
|
|





