ネット検索は第3世代に進化するか
グーグル先生を超える良回答連発、Powersetを使ってみた
2008/05/15
インターネットの検索でエポックメーキングな出来事は2度しか起こっていない。1994年にジェリー・ヤン氏らが立ち上げたヤフーがインターネットに検索をもたらしたときと、1998年にラリー・ペイジ氏らがグーグルを立ち上げ、Webページの重要度を示す「PageRank」という概念を導入したときだ。検索連動広告の発明もビジネス的には大きなステップだったが、使い勝手の向上というユーザー視点での転回点は2つだけだ。いま、ベンチャー企業の米Powersetが注目を集め、3つ目のイノベーションを起こすかどうかが注目されている。
 自然言語検索のベータ版サービスを開始した米Powerset(http://www.powerset.com/)
自然言語検索のベータ版サービスを開始した米Powerset(http://www.powerset.com/)ネット検索の歴史:数から順位への転換
Powersetが解決しようとしている問題を明確にするために、インターネットの検索エンジンの歴史を少しだけ振り返ってみよう。
グーグルが登場する以前、各検索サイトは、自分たちがいかに多くのWebページをクロールし、検索に対してどれだけたくさんの結果を返せるかを吹聴していた。例えば2000年6月のINTERNET Watchの記事を読むと、当時インターネット全体で10億ページがあり、グーグルはこのうち5億ページをインデックスしているとある。そのほか、当時まだ人気のあった検索エンジン、AltaVistaが12億ページの中から有用な6億ページをインデックスしているだとか、Inktomiが5億ページをインデックス済みで、次のバージョンアップで10億ページをカバーする計画を発表しているとある。
もはや誰も、そんな数字は口にしない。
現在、単純なクローリングで情報を引き出せないWeb上の情報、通称「ディープウェブ」と呼ばれる領域へ手を伸ばす試みが始まっている。グーグルのWebクローラーは、すでにJavaScriptエンジンを搭載したインテリジェントなものに進化しており、簡単なメニュー程度であれば機械的に展開して情報を収集できる。しかし、人間向けに作られた複雑なUIのために、クロールしきれていない情報は、まだ多いとされている。
ディープウェブの議論を置いておけば、もはや検索エンジンのカバー範囲が問題になることは、ほとんどない。インターネットに何十億ページあろうが、そのうちグーグルが何億ページをカバーしていようが、誰も気にしないだろう。グーグルが証明したのは、検索において重要なのは、どれだけたくさんの情報が出てくるかではなく、どれだけ検索キーワードと関連性が高い、重要な情報が上位に出てくるかだということだ。言い換えれば、検索結果に含まれるページの数ではなく、重要なのはページの順位ということだ。ほとんどのユーザーは検索結果の上位の5つぐらいしかクリックしないと言われている。
Powersetはページ検索ではなく情報検索
インターネット検索に3度目の転機が訪れるかも知れないと鳴り物入りで登場したのがPowersetだ(参考記事:Powerset、「質問の答え」を見つけてくれる検索エンジンをβ公開)。自然言語検索の技術を使い、通常の人間の言葉による質問に対して、それに適した回答を探し出してくれる。
5月12日に一般公開されたPowersetのベータ版を使って、早速いろいろな検索を試してみた。
グーグルとの違いをひと言で言えば、グーグルが検索キーワードに最も関連のある「ページ」を提示してくれるのに対して、Powersetは「情報そのもの」を提示してくれるということだ。
具体的にいくつか例で見てみよう。以下の例で注意してほしいのは、Powersetが現在検索対象としているのはWikipediaの英語版と、アルファ版公開中のオンラインデータベース「Freebase」だけであるのに対して、グーグルはインターネット全体が検索対象である点だ。もう1つ、以下の例ではフルセンテンスで検索したが、Powersetは1単語や単語の羅列も受け付ける。
■アルカトラズ島から逃げた囚人の数は?
「アルカトラズ島から逃げた囚人の数は?(How many prisoners have escaped from the Alcatraz Island?)」という検索に対する結果は、グーグルとPowersetで以下の通りとなった。
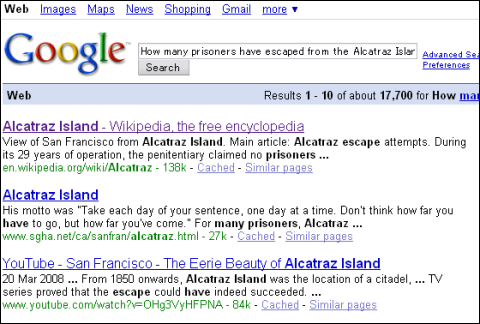 グーグルで「アルカトラズ島から逃げた囚人の数は?(How many prisoners have escaped from the Alcatraz Island?)」と検索した結果。微妙に答えらしきセンテンスが見えているが、本文に飛ばないと正解は分からない
グーグルで「アルカトラズ島から逃げた囚人の数は?(How many prisoners have escaped from the Alcatraz Island?)」と検索した結果。微妙に答えらしきセンテンスが見えているが、本文に飛ばないと正解は分からない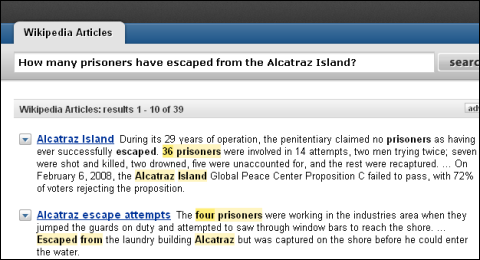 同じ検索文でPowersetで検索した結果。ずばり答えが含まれる部分が表示されている。この例では「36」は正答ではないが、少なくとも数字を聞かれていることを認識してハイライト表示していることは分かる
同じ検索文でPowersetで検索した結果。ずばり答えが含まれる部分が表示されている。この例では「36」は正答ではないが、少なくとも数字を聞かれていることを認識してハイライト表示していることは分かるグーグルはWikipediaのアルカトラズ島の項をトップに持ってきている。答えは当該ページを読めば分かる。脱獄不能と言われたアルカトラズの監獄で本当に脱獄に成功した囚人がいなかったことが分かる。従来の検索エンジンのパラダイムでは、これ以上の答えは望めない。
しかし、Powersetの出してきた答えは、これとは異なる。ずばり、関連する段落がトップに表示され、検索結果をクリックしなくても答えが分かるのだ。「how many」とフレーズを認識したPowersetは「36」という数字をハイライトしている。
ただし、ここでは正答は36人ではない。計14回あった脱獄計画に36人の囚人が関わり、誰1人として脱獄に成功していないというのが正答だ。結局人間が読まなければならないという意味では、まだ機械は人間の言葉である自然言語を理解するというレベルにはほど遠いが、それにしてもグーグルとの違いは一目瞭然だ。グーグルではアルカトラズ島の解説ページに飛んで、目でざっと読むか「escape、break、sneak」などいくつかの単語で検索して該当個所を探す必要がある。
■イルカってどうやって呼吸してるの?
 グーグル検索でトップにヒットしたページ
グーグル検索でトップにヒットしたページもう1例やってみよう。「イルカってどうやって呼吸してるの?(How do dolphins breathe?)」という検索だ。
グーグルの検索結果トップに来たのはイルカ好きのイギリス人が作った個人サイトの右のようなページだ。イルカたちが、頭のてっぺんにある潮吹き穴で呼吸するということが写真入りで端的に解説されていて、おそらくこれ以上の回答を望む人は少数派だろう。また、グーグルの検索結果では「頭のてっぺんにある潮吹き穴で呼吸する」というセンテンスがずばり検索結果のトップに表示されていて検索結果をクリックするまでもなく答えが分かる。この例ではグーグルとPowersetで差がつかなかった。
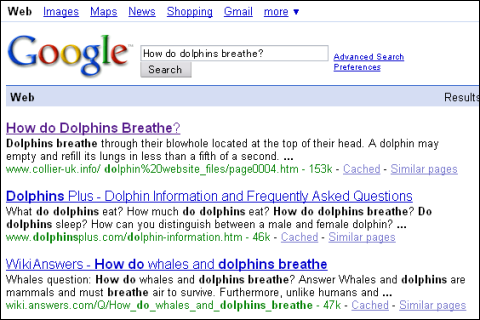 グーグルを使って「イルカってどうやって呼吸してるの?(How do dolphins breathe?)」と検索した例。ずばり端的な回答が検索結果トップの下に表示されている
グーグルを使って「イルカってどうやって呼吸してるの?(How do dolphins breathe?)」と検索した例。ずばり端的な回答が検索結果トップの下に表示されている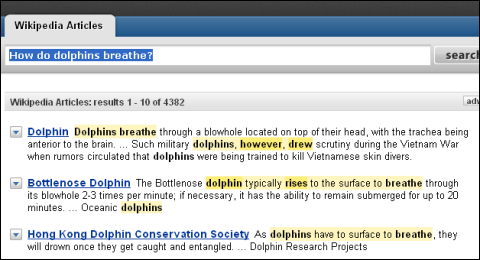 Powersetでもイルカの呼吸法について端的に説明する箇所を正しく提示できている
Powersetでもイルカの呼吸法について端的に説明する箇所を正しく提示できている■IBMのPC部門を買ったのはどこ?
次の例ではグーグルとPowersetの微妙な差が分かる。「IBMのPC部門を買ったのはどこ?(Who bought the IBM's PC division?)」という検索文だ。
グーグルでは、中国で発行される英字新聞チャイナ・デイリーの速報記事にヒットし、答えがレノボ・グループであることが検索結果をクリックするまでもなく分かる。
一方、Powersetの結果も似たようなもので、Wikipediaのレノボの項目中で該当するセンテンスがずばり検索結果のトップに表示されている。しかし、よく見ると「purchase」(購入)という語がハイライトされている。これは「purchase」(購入)が「buy」(買う)という口語的単語の同義語として扱われているということだ。従来の単なる語彙レベルの一致ではなく、Powersetでは同類語にヒットした結果も積極的に表示するという違いが見て取れる。
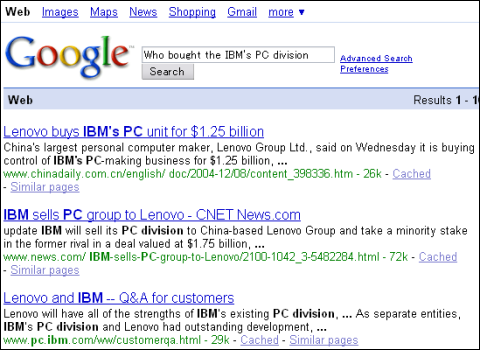 グーグルで「IBMのPC部門を買ったのはどこ?(Who bought the IBM's PC division?)」と検索した例。チャイナ・デイリーの記事にヒットし、ちゃんと必要な答えが表示されている
グーグルで「IBMのPC部門を買ったのはどこ?(Who bought the IBM's PC division?)」と検索した例。チャイナ・デイリーの記事にヒットし、ちゃんと必要な答えが表示されている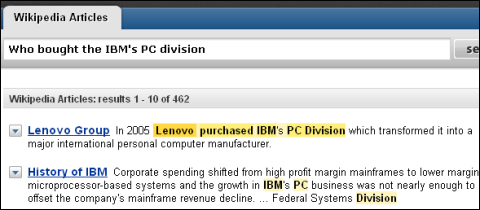 Powersetでは「purchase」(購入)という語がハイライトされており、「buy」(買う)という口語的単語の同義語として扱われていることが分かる
Powersetでは「purchase」(購入)という語がハイライトされており、「buy」(買う)という口語的単語の同義語として扱われていることが分かる■MacBook AirってUSBポートあったけ?
次の例でもずばりと答えを表示したのはグーグルではなくPowersetのほうだった。
「MacBook AirってUSBポートあったけ?(Does the MacBook Air has any USB ports?)」という検索文に対してPowersetが出してきた答えは「それに加えて、MacBook Airは1つだけしかUSBポートを持たない……(In addition, the MacBook Air offers only a single USB port...)」というセンテンスだ。
一方グーグルのほうはガジェット系ブログサイトのEngadgetがヒットした。ヒットしたエントリはAirQueueというUSB拡張デバイスに関するもので、探していた答えは含まれていなかった。Engadgetはページランクが高いのかもしれないが、求めている答えはなかった。これは、よりグーグル向けの検索方法と考えられる「MacBook Air USB」としたときでも同様だった。
グーグルを使った検索では、良質な情報を含む「ページ」がたくさん出てくるが、Webブラウザで行きつ戻りつしながら求めている「情報」を目で探すというステップで手間取るケースもある。
これはアルカトラズの監獄の例と同じことだが、重量や寸法といったデータを検索するような例でも、Powersetの威力がよりハッキリと分かる。
ただし、こうした検索例はPowersetが事実上Wikipediaだけを対象としていることによる結果でもあり、あまり公平な比較とはいえないかもしれない。また理由は定かではないが、以下の例ではグーグルのほうが、より簡単に正答(もしくは満足できる情報)を得られたと報告しておきたい。「アボカドって冷凍庫に入れなきゃいけないの?(Do I need to keep avocado in a freezer?)」「アメリカで最大の発行部数を持つ新聞は?(What's the American newspaper with the largest circulation?)」「ハリーポッターの最初のっていつ出たんだっけ?(When did the first Harry Potter come out?)」。
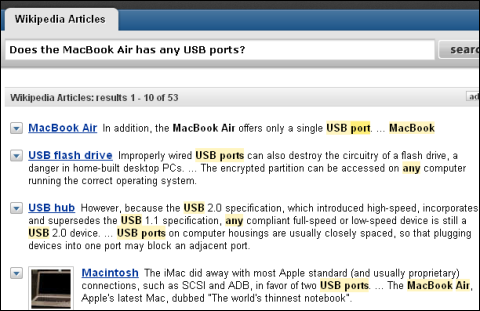 「MacBook AirってUSBポートあったけ?(Does the MacBook Air has any USB ports?)」という検索文に対してPowersetは、検索結果トップで「それに加えて、MacBook Airは1つだけしかUSBポートを持たない……」というセンテンスを提示している
「MacBook AirってUSBポートあったけ?(Does the MacBook Air has any USB ports?)」という検索文に対してPowersetは、検索結果トップで「それに加えて、MacBook Airは1つだけしかUSBポートを持たない……」というセンテンスを提示している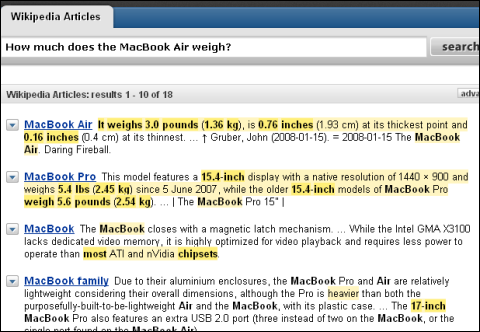 Powersetで「MacBook Airって重さどのぐらい?(How much does the MacBook Air weigh?)」と検索した例。ずばりの回答がトップに出ているほか、単位のついた数字がハイライトされているのが分かる。単に「how much」を見ているだけの可能性もあるが、見やすい結果には違いない。よく見るとメートル法の「cm」が無視されているが、これは度量衡の国際標準への移行におけるアメリカの後進性を示しているのだろう
Powersetで「MacBook Airって重さどのぐらい?(How much does the MacBook Air weigh?)」と検索した例。ずばりの回答がトップに出ているほか、単位のついた数字がハイライトされているのが分かる。単に「how much」を見ているだけの可能性もあるが、見やすい結果には違いない。よく見るとメートル法の「cm」が無視されているが、これは度量衡の国際標準への移行におけるアメリカの後進性を示しているのだろう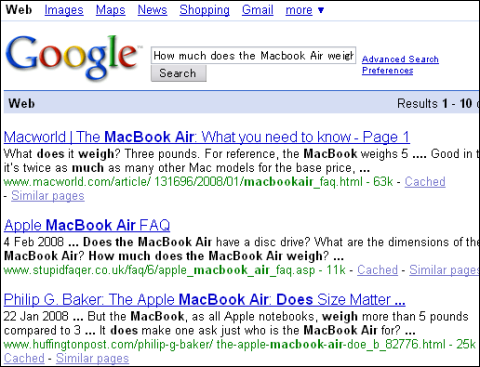 グーグルで「MacBook Airって重さどのぐらい?(How much does the MacBook Air weigh?)」と検索した結果。旧モデルのMacBookの重量がトップに出ている。2つ目の候補にはアップルのFAQサイトに含まれる該当箇所が表示されているが、画面に出ているのは回答ではなく質問文のほうだけだ
グーグルで「MacBook Airって重さどのぐらい?(How much does the MacBook Air weigh?)」と検索した結果。旧モデルのMacBookの重量がトップに出ている。2つ目の候補にはアップルのFAQサイトに含まれる該当箇所が表示されているが、画面に出ているのは回答ではなく質問文のほうだけだ「症状」で「吐き気」「頭痛」「熱」などをハイライト
Powsersetは「purchase」と「buy」のような同義語だけではなく、関連する語彙も認識するようだ。それを示すのは、次のような検索例だ。
記者は先週、サンフランシスコであったJava関連のイベントに出ていたのだが、そこでノロウイルスの感染被害が発生した。イベント会期のど真ん中、70人あまりが腹痛や嘔吐を訴えた。参加者が1万人を超える大イベントなので記者が感染する確率は低かったが、ホテルに戻ってテレビニュースで知って事態の大きさに驚いた。
気になったのはノロウイルスの潜伏期間や、それがどの程度ひどい症状を患者にもたらすかなどだ。
このくらいであれば、インターネット上のどこかに非常に良く書けた解説が軽く数十は見つかると検索する前から分かっている。そして、かなり読みやすいページがグーグルの検索結果の上位3つに含まれることも分かっている。しかし、それでも検索してから目的の情報(答え)にたどり着くまでに、Webページの構造を把握し、本文や箇条書きから正しいセンテンスを人間が目で見て探し出すというステップは残っている。
Powersetは、このステップを取り除こうとしている。
PowersetでWikipediaの項目を開くと、以下の画面のような独自インターフェイスが現れる。右側にページ全体の段落構造が表示され、検索にヒットした段落や単語、センテンスが全体のどこにあるかがハイライト表示で示されている。このインターフェイスはFlashではなくJavaScriptで書かれているようだが、非常にスムーズにスクロールする。また本文側をスクロールしても右の段落表示の画面は追随してくるため、自分が全体のどの当たりを読んでいるかが分かりやすくなっている。
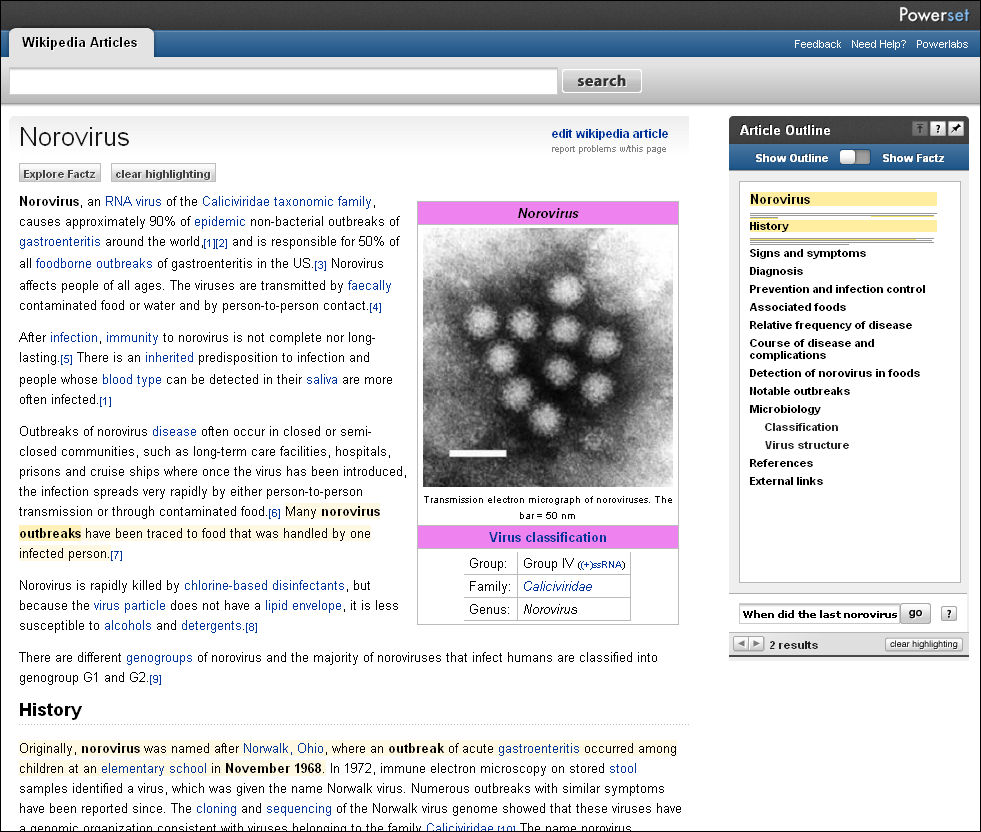 Wikipediaの項目をPowersetで表示した画面(クリックで拡大)。検索文字列に該当する箇所が本文でも右側のサマリ表示でもハイライト表示されている。右側のサマリで段落や見出しをクリックすると、本文のほうが該当箇所へジャンプする
Wikipediaの項目をPowersetで表示した画面(クリックで拡大)。検索文字列に該当する箇所が本文でも右側のサマリ表示でもハイライト表示されている。右側のサマリで段落や見出しをクリックすると、本文のほうが該当箇所へジャンプするこのダイアログボックスには検索ウィンドウがあり、ここで「症状(symptoms)」と入力すると、本文側が「兆候と症状(Signs and symptoms)」という段落に自動的にスクロールする。そして、もっとも答えに近いセンテンスが薄くハイライトされた上で、「吐き気(nausea)」「下痢(diarrhea)」「痛み(pain)」「頭痛(headache)」などが強くハイライト表示される。まさに求めていた答えだ。これはPowersetが「症状」という語が、さまざまな具体的症状を包含する上位概念であると理解していることを示している。さらに記者はノロウイルスによる死亡例があるのかどうかが気になって「die」(死ぬ)という語彙で該当項目を検索してみたのだが、「kill」(殺す)という語彙にヒットした。死ぬと殺すは同義語ではないし、単純な意味での反意語でもないが、同じグループに属しているのだろう。
Powersetは一般向けベータテスト公開前から大きな注目を集め、マイクロソフトによる買収も噂されている。それはPowersetが単に自然言語による検索が可能というだけでなく(それはどんな検索エンジンでもある程度できる)、概念や文章の構造を理解した上で適切な回答を探すという新しいアプローチが期待されているからだ。
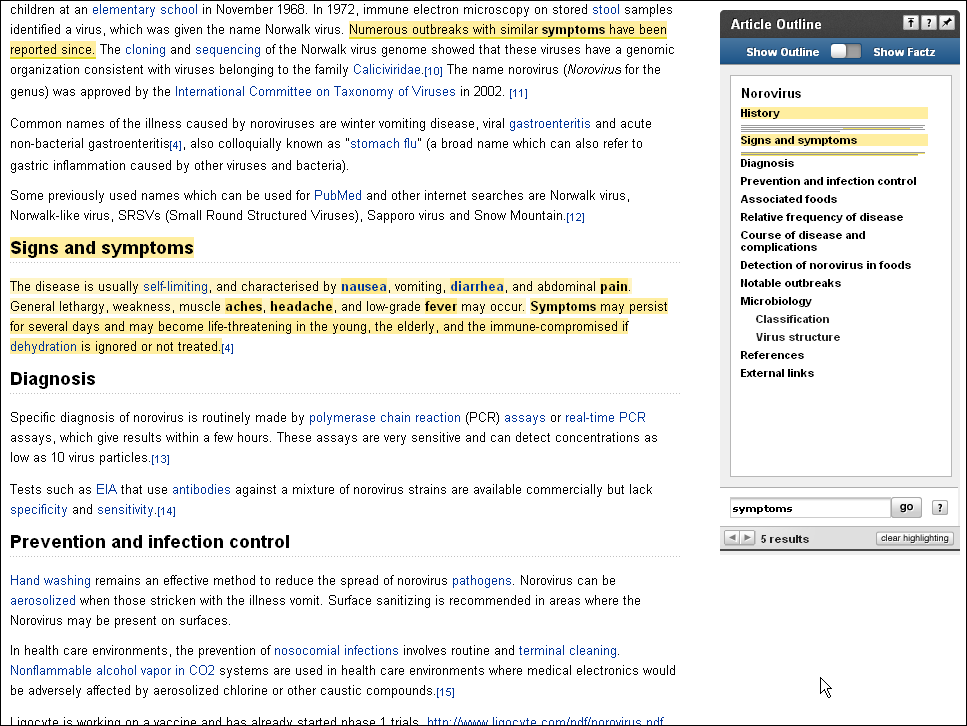 ノロウイルス(norovirus)の項目を表示した後、右側のダイアログボックスの検索で「症状」(symptoms)と入力した例(クリックで拡大)。最も重要な「段落」に一気にジャンプして「吐き気(nausea)」「下痢(diarrhea)」「痛み(pain)」「頭痛(headache)」など具体的な症状が強くハイライト表示されている
ノロウイルス(norovirus)の項目を表示した後、右側のダイアログボックスの検索で「症状」(symptoms)と入力した例(クリックで拡大)。最も重要な「段落」に一気にジャンプして「吐き気(nausea)」「下痢(diarrhea)」「痛み(pain)」「頭痛(headache)」など具体的な症状が強くハイライト表示されているPowersetは「セマンティック・アプリケーション」
Powersetの技術は「セマンティックWeb」と呼ばれる次世代Web技術を先取りした、「セマンティック・アプリケーション」(またはセマンティック・サーチ)の1種だという見方がある。
セマンティックWebは、インターネット(HTMLやXML)で、より意味論的な情報を扱えるようにするための技術や仕様の総称で、WWW(World Wide Web。Webは昔そう呼ばれていた)の生みの親であるティム・バーナーズ=リー氏が提唱したものだ。2000年頃には「次世代インターネット」としてバズワード的に騒がれた。
セマンティックWebはアカデミックな世界では盛んに研究されてきたが、まだほとんど普及していない。現在までに概念の階層構造を扱う“オントロジー辞書”や、そのマークアップのための標準的技術仕様、それに対応した処理エンジンなどが作成されているが、インターネットの世界(HTML)を作っているのは研究者たちではなく、エンドユーザーだ。エンドユーザーやWebデザイナーたちが日常的に小難しい新技術を使うと期待するのは無理がある。
トップダウン的に仕様を決め、あらゆるWebページにメタ情報(機械に分かる意味)を付けるのではなく、ボトムアップ的にインターネットをセマンティックにしていこうというのが、最近の流れだ。
その1つが「microformats」と総称されるHTMLのマークアップスタイルだ。例えば「2008/05/13」という単なる文字列が、人間だけでなく機械(Webクローラーなど)にも日付であることが分かるように、タグの属性を使って日付であることを明示する。まだmicroformatsを採用したWebサービスは多くないが、徐々に増えている。こうしたマークアップスタイルが普及すれば、検索エンジンは「2008年1月から5月までのIT関連イベント」といった検索クエリに対して、より有効な結果を提示できるだろう。
セマンティック・アプリケーションは、ボトムアップ的にインターネットをセマンティック化する動きと見ることができる。すべての人がセマンティック関連技術を利活用するようになるのは、おそらくWeb 2.0やWeb 3.0では無理で、Web 5.0ぐらいになるのではないか。そうではなく、特定領域に絞って適用すれば、それだけでも大きな成果が得られるのだから、今すぐにセマンティック技術を使おう――、それがセマンティック・アプリケーションの発想で、一群のベンチャー企業を生み出している。Powersetも、そうした企業群の1つだ。2010年までにセマンティック技術関連市場は524億ドル規模に拡大するという予測もある(参考記事:基盤が整い普及期に入るセマンティックWeb)。
Powersetが、グーグルの対抗馬となるべくインターネット全体をクロールして検索サービスを提供することになるのかどうかは分からない。むしろ、あらかじめ対象とするWebサイトの構造が分かっているときにPowersetのような検索エンジンの威力は発揮されるだろう。Powersetの検索結果画面を見れば分かるように、Wikipediaは1つのタブとなっている。Wikipiaは扱いやすい事例の1つというだけで、今後はタブを増やしていく形で、Powersetはニュースサイトや情報サービスを統合していくのではないだろうか。
例えばAmazon.comのようなeコマースサイトを対象にして「最近売れているプログラミング言語の本は何?」というような検索インターフェイスを提供できれば、売る側にも買う側にもメリットがあるだろう。旅行代理店なら「どこか南の島で来月まだ予約できるところは?」というような検索は魅力的だ。
ビル・ジョイ氏の業績を手っ取り早く調べる
Powersetには、もう1つ「Factz」という興味深いサマリー機能がある。検索語が人名や場所、会社名などの固有名詞であった場合、その基本的属性や概説が1画面に収まる形でリストアップされるというものだ。
例えば「ビル・ジョイ」(Bill Joy)のような人名を検索すると、Wikipediaの記述の冒頭と並ぶ形で誕生日や出身地、家族の名前、職業、宗教などがリストアップされる。右の欄に表示される属性情報はデータベースのFreebaseから生成している。俳優の「トム・クルーズ」(Tom Cruise)とすると、表示される属性情報には「出演した映画」として映画の名前がリストアップされる。
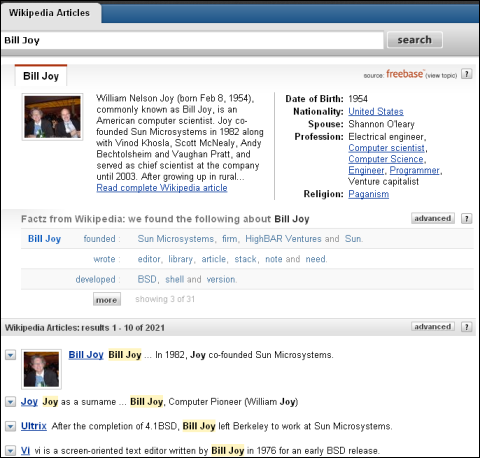 「ビル・ジョイ」(Bill Joy)のように人名で検索すると、サマリーや基本的な属性情報が表示される
「ビル・ジョイ」(Bill Joy)のように人名で検索すると、サマリーや基本的な属性情報が表示される気が利いているのはWikipediaの記述にある重要な動詞と、それに対応する名詞を認識して、それを整理した動的なインターフェイスで提供している点だ。
ビル・ジョイ氏は起業家やソフトウェア開発者として知られるが「founded(創業した)」という動詞に対して「Sun Microsystems, firm, HighBAR Ventures and Sun.」という名詞群が対応して表示されるほか、「developed(開発した)」には「BSD、shell……」などが対応して表示される。
驚くのは、この情報の元となったセンテンスが「Bill Joy (a primary developer of BSD)」となっていることだ。ビル・ジョイ氏がBSDを開発したことを意味する箇所は名詞句となっていて、developという動詞そのものは含まれていない。ここにも単純な語彙レベルのマッチングではなく、背後で意味論的な解析が行われている形跡が見て取れる。
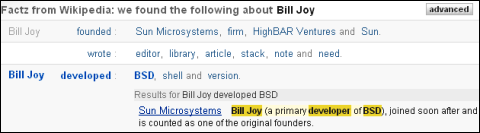 ビル・ジョイという人物が何をしたかということが「動詞+名詞」の組み合わせで一覧表示される。サン・マイクロシステムズやVCのHighBARベンチャーズなどを創立した(founded)ことや、BSDを開発した(developed)ことが分かる。developという語では動詞ではなく名詞句にヒットしていることに注目
ビル・ジョイという人物が何をしたかということが「動詞+名詞」の組み合わせで一覧表示される。サン・マイクロシステムズやVCのHighBARベンチャーズなどを創立した(founded)ことや、BSDを開発した(developed)ことが分かる。developという語では動詞ではなく名詞句にヒットしていることに注目このFactzの表示にはAjaxが使われており、適度に情報が折りたたまれて表示されている。各動詞をクリックすると、実際に該当する文章がハイライトして表示されるほか、「More」ボタンをクリックすることで表示する動詞の数を増やせる。ノイズも多いが、例えば「Bill Joy envosioned language.(ビル・ジョイは言語を構想した)」という、まるで哲学者の箴言か聖典からの引用のような、端的で、いやに鋭い項目もある(該当箇所を読んでみるとビル・ジョイ氏はMesaとC言語の良いところを組み合わせて新言語、Javaを構想したとあり、そのサマリーになっているようだ)。
Powersetはグーグルにとって脅威となるか
モバイルからSaaS、SNSまで、広範な領域で新規サービス・ソフトウェアの開発を進めるグーグルだが、検索も忘れたわけではない。現在、同社の実験サービスサイト「Google Experimental LABS」では新しい検索エンジンを公開している。
新検索エンジンでは、例えば「1980-2000」「japan」と時期や場所を指定した検索や「30〜40 inch」と長さを範囲指定した検索が可能だ。時系列に沿ってヒットしたページの量をグラフで表示する機能などもある。Powersetと異なり、情報検索というよりもページ検索を指向しているという違いが感じられるが、それでもセマンティックサーチ的な進化の方向性は見られる。
Powersetはグーグルにとって脅威となるだろうか?
すでに書いたように、Powersetがうまく結果を持ってこられるのはWikipediaやFreebaseといった特定の、しかも構造が比較的きれいなWebサイトだけを対象としているからという可能性がある。Powersetが検索対象を増やしたときに、意味のある結果を返せるかどうかは、まだ分からない。そもそもPowersetが全インターネットを対象としない可能性もあり、比較は意味がないかもしれない。
グーグルの良さはクロール頻度や順位付けノウハウ
もう1つ、現在のPowersetがほぼ静的で変更のないデータしか相手にしていないことも忘れてはならない。グーグル検索の良さは、クローリング頻度と、その順位付けにある。
ノロウイルスに続いて再び個人的体験で恐縮だが、以下のような検索ニーズに対してPowersetがどこまで応えられるかはまったく不明だ。
記者は出張中のサンフランシスコで飛び降り自殺を目撃した。正確には目撃する寸前だった。ビルの4階あたりから飛び降りようとする30絡みの男をしばらく人だかりの中で見ていたのが、おそらく1時間経っても飛び降りないだろうと、10分ほどでその場を立ち去った。その晩、別の記者から私が立ち去った5分後に男が飛び降りたと聞かされた。ただ、死なずに済んだのかどうかが分からない。
気になった記者はグーグルで「san francisco suicide」で検索した。地元新聞も見たが、関係する情報がなかなか見つからない。しばらくすると、Yahoo!のQ&Aサイトで、私とまったく同じ質問をしている人が見つかった。そこには現場にいたとする目撃者からの回答があり、読むに耐えない恐ろしい記述と、死亡したという事実が書かれていた。
こうした情報がグーグルの検索ですんなりと出てくるのは、ある種のWebサイトでのクロール頻度が高いからだろう。また、地元新聞のベタ記事にもならないできごとの伝聞情報が、ちゃんと検索で上位に表示されるのは、ページの鮮度を勘案して順位を決定しているからとだろう。「san francisco suicide」の検索に対して、サンフランシスコの自殺予防センターや、過去にゴールデンゲートブリッジから飛び降りた自殺者のリストと、「さっき起こった出来事」を同程度に優先するべき理由はある。グーグルが支持されるのは、そうした順位付けにおける各種アルゴリズムやパラメータのさじ加減が絶妙に感じられるからだろう。とすれば、Powersetのベータ版サービスは、まだこうした領域でグーグルを脅かすだけの力があるかどうか、何も証明していないということになる。
さらに、インターネット全体という巨大なデータを対象に高頻度なクローリングとインデクシングを継続するためには膨大な計算機資源とテクニックが必要だということもある。GFSやMapReduceの名で知られるグローバルな分散ファイルシステムや並列処理技術など、グーグルのインフラ面での優位については簡単に揺らぎそうもない。
Powersetとグーグルでは、もともと目指しているものが異なるのかもしれない。ただ、およそあらゆるインターネット上の検索に対して有効と考えられていた汎用的なグーグル検索に対して、有力なライバルが現れたことだけは間違いないだろう。
関連リンク
関連記事
情報をお寄せください:
最新記事
アイティメディアの提供サービス
キャリアアップ
- - PR -
転職/派遣情報を探す


「ITmedia マーケティング」新着記事
天候と位置情報を活用 ルグランとジオロジックが新たな広告サービスを共同開発
ルグランとジオロジックが新たな「天気連動型広告」を共同開発した。ルグランが気象デー...
“AI美女”を広告に起用しない ユニリーバ「Dove」はなぜそう決めたのか
Unilever傘下の美容ケアブランド「Dove」は、「Real Beauty」の20周年を機に、生成AIツー...
有料動画サービス 34歳以下では過半数が利用経験、4割は1日1回以上利用
「ニールセン・ビデオコンテンツ アンド アド レポート 2024」を基に、テレビ画面での動...
著作権はアイティメディア株式会社またはその記事の筆者に属します。(著作権について)
当サイトに掲載されている記事や画像などの無断転載を禁止します。
「@IT」「@IT自分戦略研究所」「@IT情報マネジメント」「JOB@IT」「@ITハイブックス」「ITmedia」は、アイティメディア株式会社の登録商標です。
当サイトに関するお問い合わせは「@ITへのお問い合わせ」をご覧ください。